2024-12-30
Markdown Highlighting in EVA
My syntax highlighter is quite primitive, it works on tokens on a single line and this has worked well enough for most code but it became a limitation when I wanted to add syntax highlighting to markdown.
The largest problem was that markdown uses code fences to mark multiple lines as being part of a code block. My highlighter would therefore have problems as it has no awareness of anything but the line it is currently on.
I hacked in a fix, I'm not happy with it but it does work and I think it'll be fine for most files as markdown files shouldn't get big enough to cause problems.
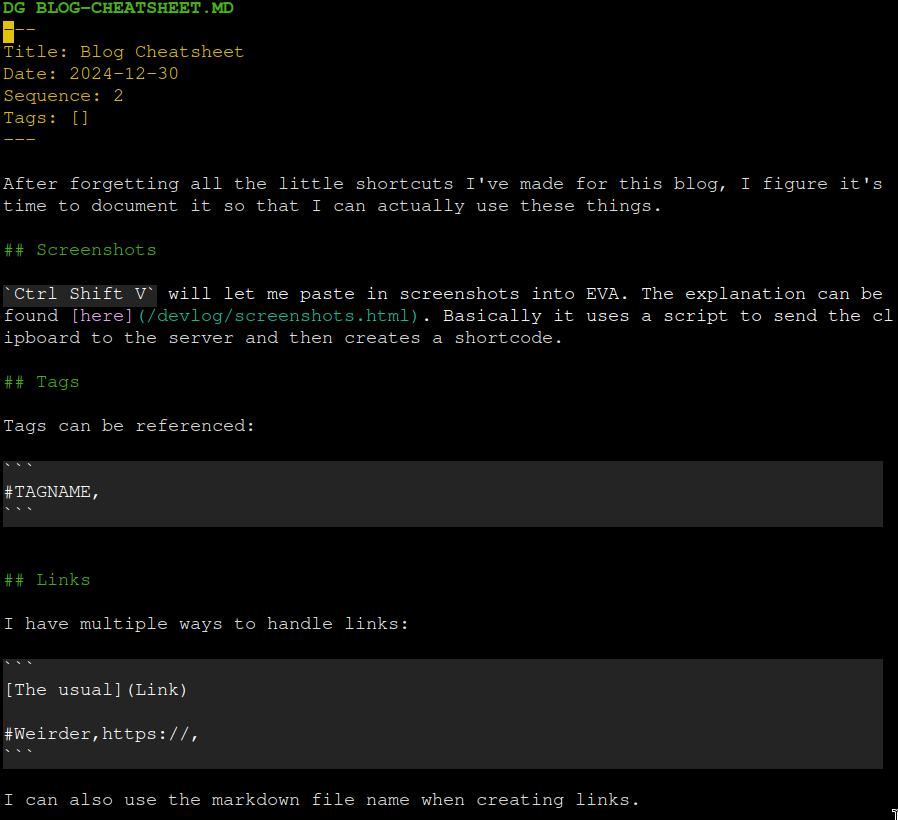
Below is a screenshot of the highlighting that happens for the YAML frontmatter, the headings, the links and code in the backticks.
The Logic
The idea is to figure out if the line I'm highlighting is in a code block or not. It turns out this is quite simple to figure out especially if I don't bother to be smart about anything. I simply find all the backticks and save their position when displaying any line. This means that there is a ton of waste as the code to do the highlighting runs constantly.
I find all the code fences and then check if the current line falls in between the fences. If it does, then the line get's the code block highlighting. There are some optimizations I could do, such as caching the code blocks and updating them only when they change. This would remove a lot of the waste. However EVA is a code editor first and markdown editor second so I'm hesitant to add complexity that I think is not worth it.
This little endevaor has made it pretty clear that my editor has architectural problems. Long lines for instance are handle poorly and result in weird highlighting issues.
A future goal is to have code highlighting inside a code block. I think that would be quite nice but that is a longer term goal. Another goal is to add a dictionary so that I could get some spell check going. Something to check grammar would also be nice.
The Code
The code in all it's ugliness:
********************* S U B R O U T I N E *********************
*
TOKENIZE.LINE.MARKDOWN:NULL
*
INSIDE.CODE.BLOCK = FALSE
*
MD.CODE.PAIRS = ''
NUMBER.OF.RAW.LINES = DCOUNT(RAW.LINES,@AM)
*
FOR MD.LINE.CTR = 1 TO NUMBER.OF.RAW.LINES
MD.LINE = RAW.LINES<MD.LINE.CTR>
*
IF MD.LINE[1,3] = '```' THEN
START.CODE.BLOCK = MD.LINE.CTR
*
MD.LINE.CTR = MD.LINE.CTR + 1
MD.LINE = RAW.LINES<MD.LINE.CTR>
*
LOOP UNTIL MD.LINE[1,3] = '```' OR MD.LINE.CTR > NUMBER.OF.RAW.LINES DO
MD.LINE.CTR = MD.LINE.CTR + 1
MD.LINE = RAW.LINES<MD.LINE.CTR>
REPEAT
*
MD.CODE.PAIRS<-1> = START.CODE.BLOCK : @VM : MD.LINE.CTR
END
NEXT MD.LINE.CTR
*
NUMBER.OF.CODE.BLOCKS = DCOUNT(MD.CODE.PAIRS,@AM)
*
FOR MD.BLOCK = 1 TO NUMBER.OF.CODE.BLOCKS
CODE.BLOCK = MD.CODE.PAIRS<MD.BLOCK>
IF LINE.NUMBER >= CODE.BLOCK<1,1> AND LINE.NUMBER =< CODE.BLOCK<1,2> THEN
INSIDE.CODE.BLOCK = TRUE
END
NEXT MD.BLOCK
*
IF INSIDE.CODE.BLOCK THEN
LINE = BACKGROUND.BLACK : LINE : STR(' ',80 - LEN(LINE)): RESET.COLOR
RETURN
END
*
IF LINE[1,1] = '#' THEN
LINE = STMT.COLOR : LINE : FOREGROUND.COLOR
END
*
I'm not happy with this code because I think there is an easier solution that I'm missing and the code is a bit convoluted. The variable naming also isn't great and I rushed to finish this.